God praksis for udvikling af machine learning-modeller
Machine learning-modeller kan være med til at forbedre diagnostik, identificere risikopatienter, målrette behandling og forudsige behandlingernes effekt. Men der er mange faldgruber i udviklingen af disse modeller, og som sundhedsprofessionel kan det være relevant at have en forståelse for disse.

Kunstig intelligens og herunder machine learning (ML) har potentiale til at revolutionere sundhedssektoren på mange områder. Vi indsamler store mængder data på patienterne, og ML kan bruges til at behandle og forstå komplekse sammenhænge i disse data på en systematisk, fleksibel og skalérbar måde. Disse modeller er i stand til at analysere forskellige typer data, herunder demografiske oplysninger, laboratorieresultater, billedundersøgelser, lægenotater og data fra wearables, hvilket gør ML velegnet til en bred vifte af opgaver. Modellerne kan blandt andet bruges til at identificere risikopatienter, stille diagnoser, vurdere behandlingsmuligheder og forudsige behandlingers effekt. Der ses allerede i dag mange eksempler på, hvordan disse modeller implementeres i klinisk praksis som en hjælp til sundhedsprofessionelle i deres daglige arbejde med behandling af forskellige patientgrupper. For eksempel inden for radiologi, hvor ML kan være med til at segmentere patologisk væv.
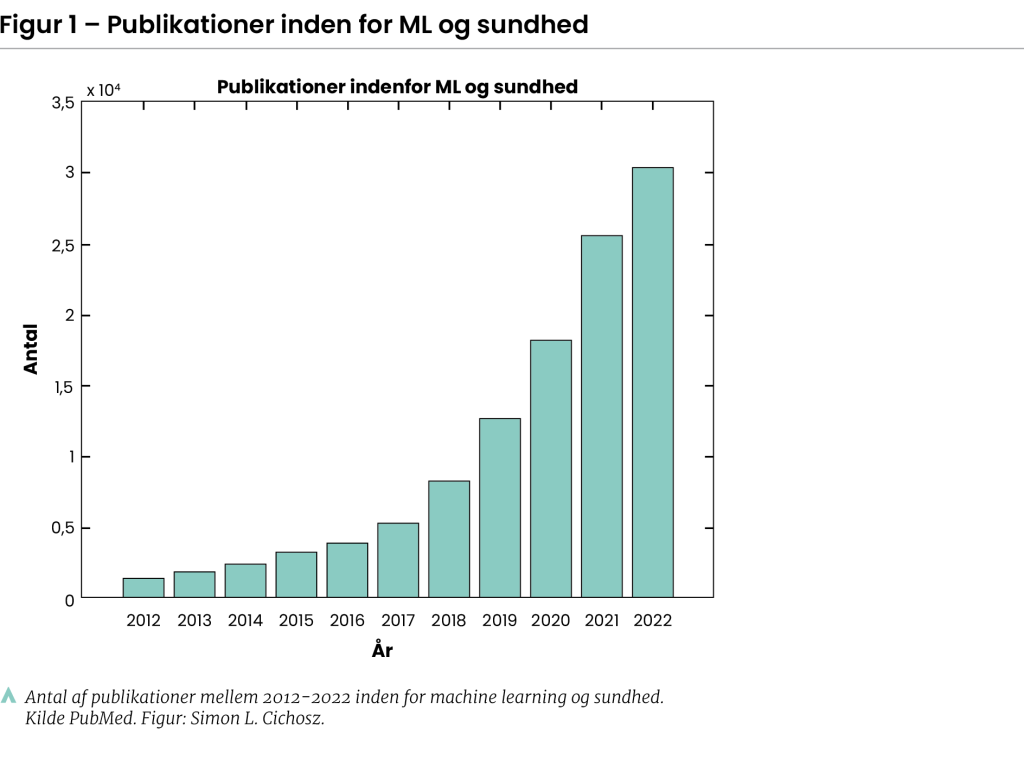
De seneste ti år er der i den videnskabelige litteratur sket en markant stigning af publicerede artikler med fokus på udvikling og brug af ML. I 2012 blev der publiceret omkring 1.500 artikler på området, og i 2022 blev der publiceret over 30.000 artikler (se figur 1, kilde PubMed). Dette enorme antal står ikke helt mål med den faktiske udbredelse af teknologien i den primære og sekundære sektor. ML’s begrænsede anvendelse i klinisk praksis tyder på, at de nuværende strategier for udvikling af ML er mangelfulde. I øjeblikket udvikles ML-løsninger ofte i siloer med manglende fokus på alle de aspekter, der er nødvendige for at kunne blive implementeret som en løsning på en klinisk problemstilling. Undersøgelser på området har også vist, at mange af de publicerede studier, der udvikler og anvender ML, mangler vigtige informationer for at kunne vurdere deres relevans og validitet.
Som sundhedsprofessionel kan det være relevant at kende til, hvilke aspekter der er vigtige at tage højde for i udviklingen af en ML-løsning for at kunne vurdere disse løsninger bedre.
God machine learning-praksis
I 2021 publicerede The U.S. Food and Drug Administration (FDA) i samarbejde med en række andre myndigheder ti guidelines for udvikling af god machine learning-praksis (GMLP). Disse vejledende princippers formål er at hjælpe med at fremme sikker og effektiv udvikling af medicinsk udstyr, der bruger kunstig intelligens og machine learning.
Forstå problemet, før du udvikler ML-løsninger
Det er vigtigt at forstå det problem, man gerne vil løse. Dette kræver inddragelse af relevante kliniske fagpersoner og en forståelse af de kliniske arbejdsgange. Det ses derfor ofte, at de udviklede ML-løsninger ikke er brugbare til at løse den kliniske problemstilling i den virkelige verden. For eksempel kan et system til vurdering af dødelighed på intensivafdelinger være med til målrette behandlingen for patienter i en højrisikogruppe – men hvis et system bruger data fra patienterne sent i forløbet, er det måske for sent at gøre en klinisk forskel.
Vigtigheden af at forstå data som input til en ML-model
Det er vigtigt at forstå de data, der bruges som input til en ML-model. Er disse data tilgængelige for modellerne på det tidspunkt, de ønskes brugt, hvad er kvaliteten af de brugte data, og kan de variere over tid eller fra afdeling til afdeling? Hvis det ønskes at anvende diagnosekoder, er de så altid den korrekte afspejling af den underliggende problemstilling for patienten, eller hvad er kvaliteten af et blodtryk målt hos praktiserende læge kontra et blodtryk målt af patienten i eget hjem? Det er essentielt, at man forstår baggrunden for de data, der bruges, og at det sikres, at kvaliteten af data er høj.
Etiske overvejelser i udvikling og implementeringen af et ML-system
Etiske overvejelser er ligeledes vigtige at medtage. Der ses blandt andet en tendens til, at patienter med mere overskud også i højere grad er bedre til at måle og levere sundhedsdata til sådanne systemer. Et ML-system kan være med til at vurdere, hvilke patienter der vil have gavn af et givent behandlingstilbud. Men hvis denne vurdering forudsætter levering af data, kan det medføre en øget skævvridning mellem patienterne og dermed ulighed i sundhed. Etiske overvejelser bør derfor altid være en central del af udvikling og implementering af et ML-system.
Metodisk tilgang til at vurdere en ML-models præstation
Det kræver også en god metodisk tilgang at vurdere, hvor godt en ML-model præsterer. Derfor inddeles data oftest i minimum to datasæt: træning og testsæt. Dette skyldes, at en model godt kan være udviklet optimalt til en problemstilling i et træningsmiljø, men ikke vil præstere nær så godt på hidtil usete data – et koncept, der betegnes som ”overfitting” (til træningssættet). Det kræver omhyggelig behandling af data for at sikre, at der ikke sker utilsigtet lækage mellem de datasæt, der bruges til modeludvikling, og til den efterfølgende validering på hidtil usete data. Derfor bør data opdeles på patientniveau, således at data fra samme patient ikke optræder i både trænings- og valideringssæt, og data bør indeholde tilstrækkelige mændger data til at afspejle den ønskede målgruppe af patienter. Modellerne bør også altid valideres i den population, de ønskes anvendt på. En model, der kan prædiktere risikoen for sepsis i en voksen patientgruppe, kan eksempelvis ikke forventes at kunne overføres til en gruppe, der består af pædiatriske patienter. Det er også vigtigt at forstå, at forudsætningerne for en model kan ændre sig over tid – derfor er det GMLP’s anbefaling, at disse modeller vurderes og opdateres løbende igennem deres livscyklus.
Vælg statistiske mål med forsigtighed ved vurdering af en ML-models ydeevne
De statistiske mål, der bruges til at vurdere en models ydeevne, bør også vælges med forsigtighed. Ofte præsenteres en kurve med 1-specificitet som funktion af sensitivitet (ROC, receiver operating characteristics) som mål for modellens evne til at klassificere sygdom. Den giver et overblik over evnen til at adskille syge fra raske, men den tager ikke højde for prævalens af sygdommen i den undersøgte population. Det kan i værste fald betyde, at modellen klassificerer mange raske som syge for hver korrekt klassificeret syg patient. For en sygdoms regression, hvor man vil prædiktere en værdi for patienten, bør man ikke kun rapportere den gennemsnitlige ydeevne, men også vurdere, om visse områder af spektret har forskellige evner til at prædiktere værdierne for patienterne. For eksempel ved modeller, hvor det ønskes at prædiktere fremtidige glukoseniveauer for patienter med diabetes, bør fejlen også vurderes særskilt, afhængigt af, om patienten oplever lave eller høje glukoseniveauer. Her er den acceptable grænse for fejl lavere, hvis patienten oplever hypoglykæmi frem for hyperglykæmi.
Effekten af ML-systemerne bør også undersøges. Selvom en model har vist en god evne til at prædiktere en given hændelse, for eksempel risiko for sepsis, så bør den kliniske effekt også vurderes. Er brugerens interaktion med systemet og handlinger ud fra beslutningsstøtten som antaget? Påvirker dette den kliniske effekt? – i tilfældet med sepsis, vil patienterne så have en højere overlevelserate efter implementering af systemet? Effektiv anvendelse af en ML-model på en etisk, juridisk og moralsk ansvarlig måde kan være vanskeligere end at udvikle en model i et eksperimentelt miljø.
Før en ML-model integreres i patientbehandling, er det afgørende at teste systemet i ”silent mode”, hvor forudsigelser foretages i realtid og vurderes af kliniske eksperter. Denne prospektive validering giver klinikere mulighed for at identificere fejl og mangler. Efter prospektiv validering kan effektiviteten af modellen i kliniske studier evalueres. Randomiserede kontrollerede forsøg er ofte den bedste måde at evaluere effektiviteten på.
Konklusion
Kunstig inteligens og herunder machine learning (ML) har potentiale til at revolutionere sundhedssektoren på mange områder. Men det er vigtigt at kende til de faldgruber, der kan være ved at udvikle og implementere disse løsninger i klinisk praksis, hvis potentialet skal indfries.
-
Referencer
- Yusuf M, Atal I, Li J, et al. Reporting quality of studies using machine learning models for medical diagnosis: a systematic review. BMJ Open 2020;10:e034568. DOI:10.1136/BMJOPEN-2019-034568
- Good Machine Learning Practice for Medical Device Development: Guiding Principles | FDA. https://www.fda.gov/medical-devices/software-medical-device-samd/good-machine-learning-practice-medical-device-development-guiding-principles
- Wiens J, Saria S, Goldenberg A. Do no harm: a roadmap for responsible machine learning for health care. Nature Medicine volume 25, pages1337–1340 (2019). DOI:10.1038/s41591-019-0548-
Relateret indhold









Brænder du for at skrive?
Vil du gerne dele din forskning eller dine kliniske erfaringer med dine kollegaer inden for netop dit speciale? Har du en ide til en artikel, som du gerne vil udgive hos os? Send redaktionen en mail på redaktion@bpno.dk
Send mail til redaktionen